问题分类
- CPU问题
- 机器负载高
- CPU消耗高
- 响应时长高
- 资源消耗低,但是压力上不去
- 上下文切换频繁,cache miss率高
- 锁冲突严重
- 磁盘IO问题
- IO 消耗太多,引起系统影响慢
- 大量随机IO
- 句柄泄露
- swap引起系统响应变慢
- 写入磁盘的数据丢失,磁盘损坏等
- 网络IO问题
- 网络不通
- 延迟大
- 网络超时,丢包
- 连接异常
- 大量无效数据
- 网卡跑满
- CPU处理网卡中断繁忙
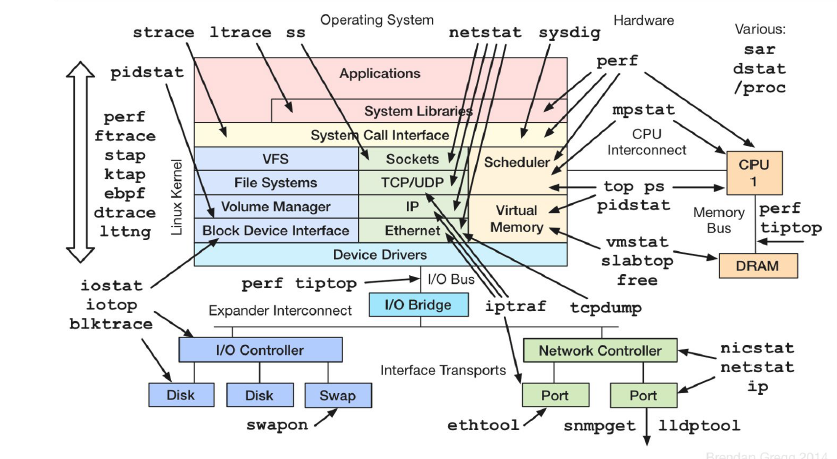
CPU 问题诊断与调优
CPU负载分析 - uptime
~$ uptime
21:17:43 up 0 min, 0 users, load average: 0.52, 0.58, 0.59
输出解释
- up 0 min 机器已经启动多久
- 0 users 当前登录的用户数
- load average 过去1分钟,5分钟,15分钟的负载情况
什么是负载?
- 正在执行的进程数(当前正在使用CPU) + 处于执行队列中的进程数(只要调度到就马上执行) + 不可中断的进程数目(一般是等待IO完成)
这三个值的综合要小于 2 * cpu逻辑核,否则可能遇到了严重的性能问题,如CPU资源不足或者IO太慢,阻塞了太多进程
此命令可以作为最先执行的命令进行粗略分析
CPU负载分析 - vmstat
vmstat 1(1秒钟输出一行)
[~]$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 5413088 667908 9334568 0 0 0 9 0 0 0 0 100 0 0
[~]$ vmstat 1 (1秒输出一行)
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 5413408 667908 9334504 0 0 0 9 0 0 0 0 100 0 0
0 0 0 5413392 667908 9334504 0 0 0 116 3456 5301 0 0 100 0 0
0 0 0 5413392 667908 9334504 0 0 0 0 3465 5274 0 0 100 0 0
0 0 0 5413392 667908 9334504 0 0 0 0 3287 5132 0 0 100 0 0
0 0 0 5413020 667908 9334504 0 0 0 0 3596 5675 0 0 99 0 0
0 0 0 5413020 667908 9334504 0 0 0 0 3803 5677 0 0 100 0 0
第一行是系统自启动以来的平均值,一般忽略
- r: 可执行的线程数量,正在执行和处于执行队列的都算在内
- b: D状态处于IO阻塞状态的线程数量,如果过大则说明较多的线程在等待IO
- memory:内存信息
- swap: 页面的换入换出个数,如果不为0则表示内存不够,性能杀手,建议关闭
- IO: 每秒多少个磁盘块(block)的读写
- System:in 表示中断的数目,cs表示进程上下文切换的次数,进程上下文切换代价是很大的,实时应用应该要降低
- cpu:us用户态,sy系统态,id空闲态,wa等待io(此时CPU也可以算是空闲) 时间分配比例
CPU负载分析 - top
top - 10:33:49 up 139 days, 18:39, 1 user, load average: 0.00, 0.03, 0.05
Tasks: 154 total, 1 running, 153 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16171652 total, 5410500 free, 757516 used, 10003636 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 14242684 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 第一行显示结果与uptime一致
- 第二行,tasks表示当前有多少进程,及各个状态下进程的数量
- 第三行将cpu消耗按百分比进行了分类
- us:用户态占用CPU百分比
- sy:内核态占用CPU百分比
- ni:改变过优先级的进程占用CPU百分比
- id:空闲CPU百分比
- wa:IO等待占用CPU百分比
- hi:硬中断占用CPU百分比
- si:软中断占用CPU百分比
top 常见用法:
- 只针对指定进程进行top观察: top -p [pid]
- top默认按cpu消耗排序,输入M,可以使结果按内存消耗排序
- top默认3秒刷新一次,输入 d 0.1 可以使结果0.1秒刷新一次
- 在top中输入H,可以按子线程现实详细信息
- 输入1可以显示每个cpu的统计信息
CPU负载分析 - strace
strace -tttT -v -s10 -f -p [pid]
strace -e brk,mmap -f -p [pid]
可以用于分析各个进程子线程的系统调用,每个系统调用的执行时间
也可以指定只监控某些系统调用,比如 mmap
notice: 这个命令对性能的影响非常大,尽量不要在现网执行
CPU瓶颈分析 - perf
- 可以用于分析热点函数
perf top -g -p [] - 性能分析结果保存起来
perf record -F 99 -g -p [pid] --sleep 60 - perf report 输出热点函数信息图
精准到函数的性能分析 - 火焰图
根据perf的输出,使用火焰图来进行性能分析
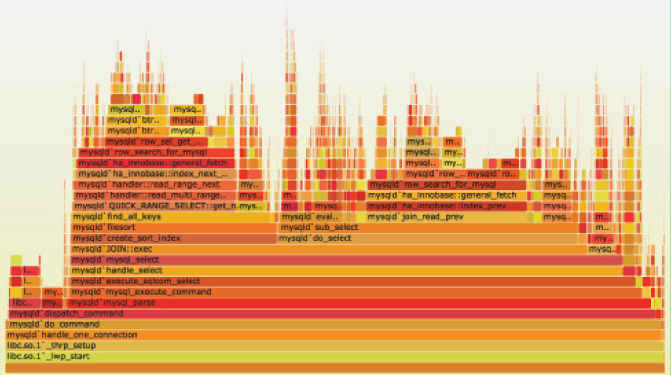
- 越高表示调用栈越深,如果出现平顶,则表示该函数可能存在性能问题
通过valgrind分析程序性能
valgrind --tool=callgrind --separate-threads=yes ./testop -r -w -D -t 60
让程序执行60秒后退出,将统计信息保存到 callgrind.out.xxxx 文件中,然后使用KcacheGrind分析
对函数堆栈进行快速分析
pstack 打印程序的堆到文件
pstack [pid] > p
pt-pmp 对堆栈信息进行汇总观察
pt-pmp p
CPU问题分析总结
- 粗看系统负载情况: uptime, vmstat 【可用在线上环境】
- 实时cpu资源消耗情况:top 【可用在线上环境】
- 分析系统调用:strace
- 分析函数热点,生成火焰图:perf 【可用在线上环境】
- 分析各个线程的资源消耗情况:valgrind
- 分析各个线程的堆栈执行情况:pstack & pt-pmp
内存问题诊断与调优
内存问题分类
- 内存重复释放
- 释放的不是动态分配的内存,如栈上的内存
- 读写已经释放的内存
- 读写没有分配的内存
- 内存耗尽,分配失败
- 读写内存超越边界,尤其是对于栈上的局部变量数组
- 内存泄露
- malloc,free 与new,delete 混用
- new [] 分配, delete 释放
- 变量没有初始化
- 频繁的内存分配引起碎片和性能问题
开发要求
- 尽量避免手动管理指针,使用 shared_ptr、unique_ptr 等智能指针
内存诊断工具 - valgrind
valgrind --tool=memcheck --leak-check=full --show-reachable-yes ./testperf -t120 >memeory.txt 2>&1
最后打开 memory.txt 分析
内存泄露定位 - mtrace
- 编译时加上 -g 标记,如:
g++ a.cpp -g -o a.out - 使用:
mtrace a.out xxx.log
为多线程优化的通用内存库-jemalloc/tcmalloc
- 多线程
- 程序内部有大量内存分配,比如使用大量STL,string等
- 需要做性能和内存走profile等场景
free 命令观察系统内存使用情况 free -hw
[~]$ free -hw
total used free shared buffers cache available
Mem: 15G 739M 5.2G 1.0G 652M 8.9G 13G
Swap: 0B 0B 0B
- Mem:应用能够使用的总物理内存
- Swap:机器swap分区的内存
- total:总的物理内存
- used:已经使用的内存(total - free - buffers - cache)
- free:没有使用的内存,不包括buffers/cache,所以必要时OS可以释放出更多的可用内存
- shared:共享内存
- buffers:磁盘数据的缓存
- cache:文件的页面缓存,提升读写效率
- available:应用真正能使用的内存,一般为free+cache中能被回收的内存
主动清理page cache
查看脏页数量: cat /proc/vmstat | grep nr_dirty
刷脏页:sync
清理page cache:echo 1>/proc/sys/vm/drop_caches
总结
- c++ 开发必须掌握智能指针
- 熟练使用 valgrind 分析内存泄露
- 了解多线程内存库 jemalloc / tcmalloc,可以熟悉一下 jemalloc 源代码
- 会分析free的结果
- 建议关闭swap
- 熟悉
/proc/sys/vm下的参数,比如刷脏页的频率,脏页占有量, swappinness 等
IO 问题诊断与调优
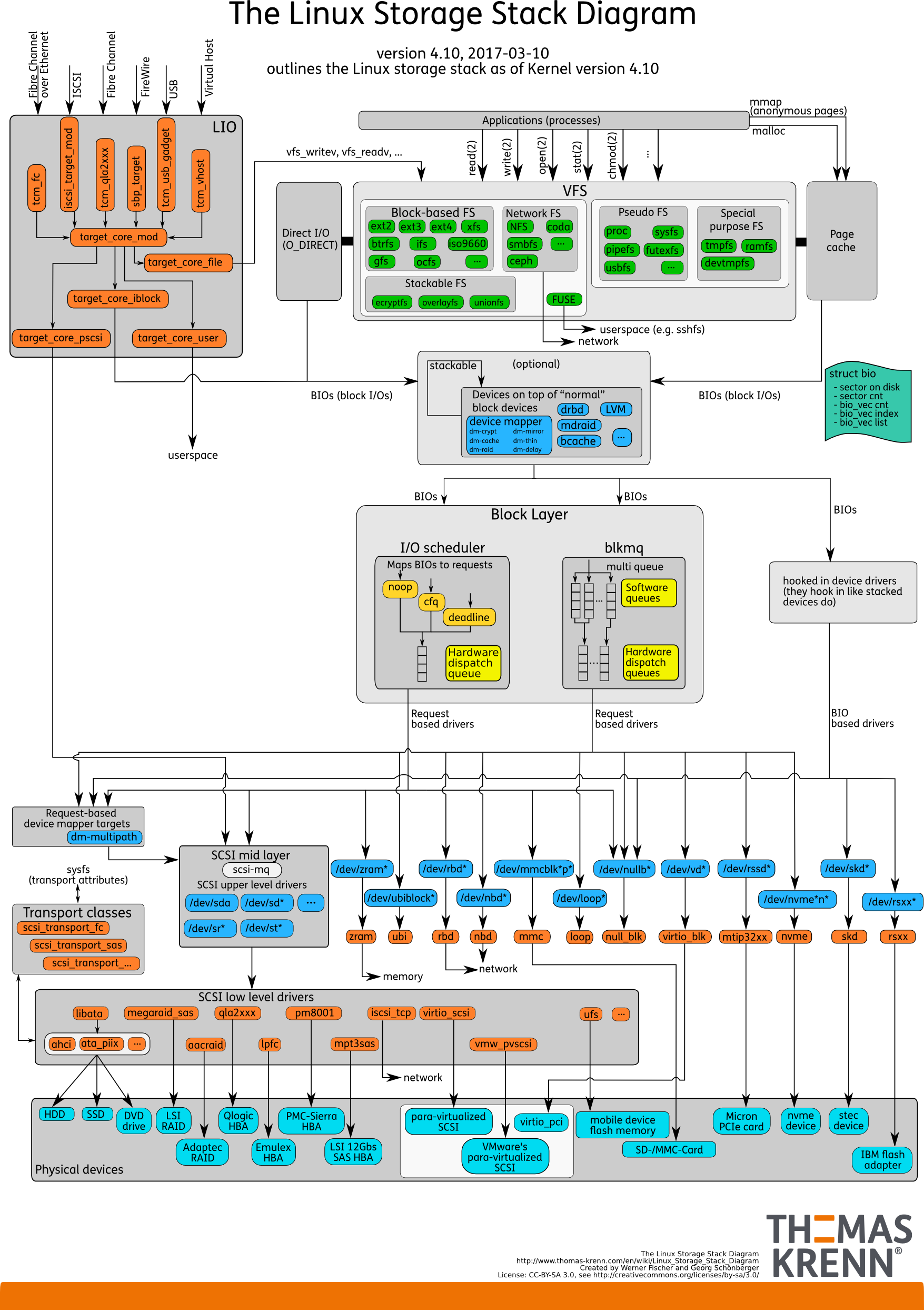
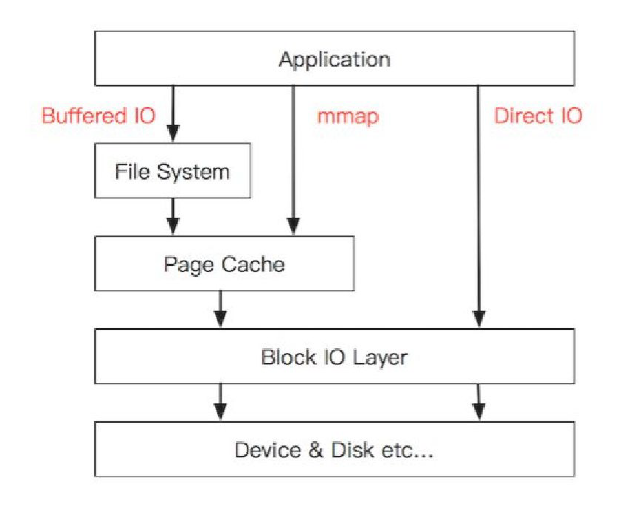
重要概念
- 顺序 IO:顺序读写文件,是性能最好的读写模式,一般适用于日志类场景
- 随机 IO:随机读写,机械硬盘性能很差,这种场景建议使用SSD,应用层尽量将随机IO改成顺序IO
- fsync 刷盘:为了数据安全,每次完成通过 fsync 做强制刷盘操作,避免机器宕机丢失数据,但这个操作对吞吐和响应延迟影响比较大,一般会采用批量合并fsync来优化
- direct IO:绕过 page cache ,直接对设备进行读写,性能不如 page cache,适用于业务层做个 cache 的场景,比如数据库
- aio :异步 io,读写操作异步化,一般也 direct IO,编程复杂,对于大部分应用不要采用,适用于数据库场景
测试磁盘IO性能 - dd
- 测试写,direct & sync 顺序写
rm testfile; dd if=/dev/zero of=testfile bs=4k count=30000 oflag=direct,sync - 测试写,direct 顺序写
rm testfile; dd if=/dev/zero of=testfile bs=4k count=30000 oflag=direct - 测试写,page cache 顺序写
rm testfile; dd if=/dev/zero of=testfile bs=4k count=30000 - 测试读,page cache 顺序读
dd if=testfile of=/dev/null bs=4k count=30000 - 测试读,direct 顺序读
dd if=testfile of=/dev/null bs=4k count=30000 iflag=direct - 结果:
[~]$ rm testfile; dd if=/dev/zero of=testfile bs=4k count=3000 oflag=direct,sync 3000+0 records in 3000+0 records out 12288000 bytes (12 MB) copied, 7.45694 s, 1.6 MB/s [~]$ rm testfile; dd if=/dev/zero of=testfile bs=4k count=3000 oflag=direct 3000+0 records in 3000+0 records out 12288000 bytes (12 MB) copied, 2.38652 s, 5.1 MB/s [~]$ rm testfile; dd if=/dev/zero of=testfile bs=4k count=3000 3000+0 records in 3000+0 records out 12288000 bytes (12 MB) copied, 0.00910429 s, 1.3 GB/s [~]$ dd if=testfile of=/dev/null bs=4k count=3000 3000+0 records in 3000+0 records out 12288000 bytes (12 MB) copied, 0.00310101 s, 4.0 GB/s [~]$ dd if=testfile of=/dev/null bs=4k count=3000 iflag=direct 3000+0 records in 3000+0 records out 12288000 bytes (12 MB) copied, 0.901235 s, 13.6 MB/s - fio命令测试随机读写性能
- 16线程采用异步io,队列深度为1的随机写
fio --thread --directory=. --size=1000M -iodepth 1 --iodepth_batch_submit=1 -rw=randwrite -bs=4k -ioengine libaio -direct=1 -numjobs=16 --name testfio - 16线程采用异步io,队列深度为16,batch为8的随机读
fio --thread --directory=. --size=1000M -iodepth 16 --iodepth_batch_submit=8 -rw=randwrite -bs=4k -ioengine libaio -direct=1 -numjobs=16 --name testfio - 16线程采用pwrite普通IO随机写
fio --thread --directory=. --size=1000M -rw=randwrite -bs=4k -ioengine psync -direct=1 -numjobs=16 --name testfio
- 16线程采用异步io,队列深度为1的随机写
观察磁盘IO状况 iostat
$ iostat -x -m -t 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.27 0.00 0.09 0.01 0.00 99.63
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 2.87 0.01 1.78 0.00 0.06 68.93 0.01 2.98 5.29 2.97 0.52 0.09
vdb 0.00 0.36 0.06 0.16 0.00 0.01 134.40 0.01 30.91 1.89 42.33 0.60 0.01
scd0 0.00 0.00 0.00 0.00 0.00 0.00 7.27 0.00 0.36 0.36 0.00 0.36 0.00
- rrqm/s 设备列表里每秒合并读请求次数
- wrqm/s 设备列表里每秒合并写请求次数shan’qu
- r/s 合并之后设备每秒实际提供的读次数
- w/s 合并之后设备每秒实际提供的写次数
- rMB/s 设备提供的每秒读的数据大小
- wMB/s 设备提供的每秒写的数据大小
- avgrq-sz 设备平均每次操作的扇区数目
- avgqu-sz 设备队列中保存的IO数目的平均值,值越大表示阻塞越严重,超过1表示IO请求有堆积,设备处于饱和状态
- await IO进入队列到处理完成的总时间,单位为毫秒
- r_await 读IO进入队列到处理完成的总时间,单位为毫秒
- w_await 写IO进入队列到处理完成的总时间,单位为毫秒
- svctm 每次IO平均处理时间,单位为毫秒
- %util 设备IO利用率,超过60%表示已经比较繁忙了,100%就饱和了
IO问题分析 - 观测进程 IO 和 句柄 iotop
iotop观察各个进程的 IO 消耗情况ls /proc/[pid]/fd -l查看进程句柄情况lsof -p [pid]查看进程句柄的情况
总结
- IO 执行栈
- IO 相关的重要概念,如顺序 IO ,随机 IO ,同步,异步等
- 使用 dd 和 fio 测试 IO 的性能
- iostat 输出结果会解读
- iotop 观察具体进程 IO 的消耗情况
- 通过 proc 文件系统和 lsof 分析句柄的使用,定位是否有句柄泄露,某个句柄具体对应哪个文件
网络问题诊断与调优
netstat -apn | grep [pid]查看机器网络连接信息lsof -i :[port]查看开了这个端口的进程sar -n DEV -n EDEV 1查看网卡流量和包量- IFACE 网卡设备名字
- rxpck/s 每秒收到包的数量
- Txpck/s 每秒发包的数量
- rxkB/s 每秒收到了多少kB的包
- txkB/s 每秒发送了多少kB的包
tcpdump -AAXn -s1000 -iany port 4100抓包tcpdump -AAXn -s1000 -iany port 4100 -w tcp.datatcpdump输出到文件通过 wireshark 进行分析
总结
- 通过 netstat 查看网络连接状况
- lsof 分析具体端口被谁占用
- 通过 sar 查看网卡流量
- 熟练掌握 tcpdump & wireshark 进行网络包的分析
其他
CPU,内存,IO,网络综合展示工具 dstat
dstat -t -a --proc-count -i -l -m -p --aio --disk-util 10dstat -t --disk-util -s --fs --socket --tcp --udp --top-bio --top-cpu 10
综合系统运行信息 - sar
- sar命令负责收集汇报存储系统运行信息
- -d可以查看io的信息
程序调试 gdb
- gdb ./testperf 通过调试的方式启动程序
- gdb -p [pid] 对指定的进程进行调试
- gdb testperf core-testperf-xxx-xxxxx 程序异常退出产生core,可以用来调试
core文件的tips:
- 执行程序之前先确保开启了core ulimit -c unlimited
- man core查看更多关于控制core文件生成的规则
编译参数
- gcc -g 指定程序在编译时包含调试信息
- -ggdb3
- -O0 #0级别调试最方便,但性能不是最佳,正式环境一般用 -O2或者 -O3
Linux系统错误日志
对于系统异常,linux会打印日志
- vim /var/log/messages 分析故障时间点的异常信息
死锁检测
死锁的四个条件
- 互斥条件
- 阻塞
- 不抢占
- 循环等待
一个交叉持锁的死锁情况:
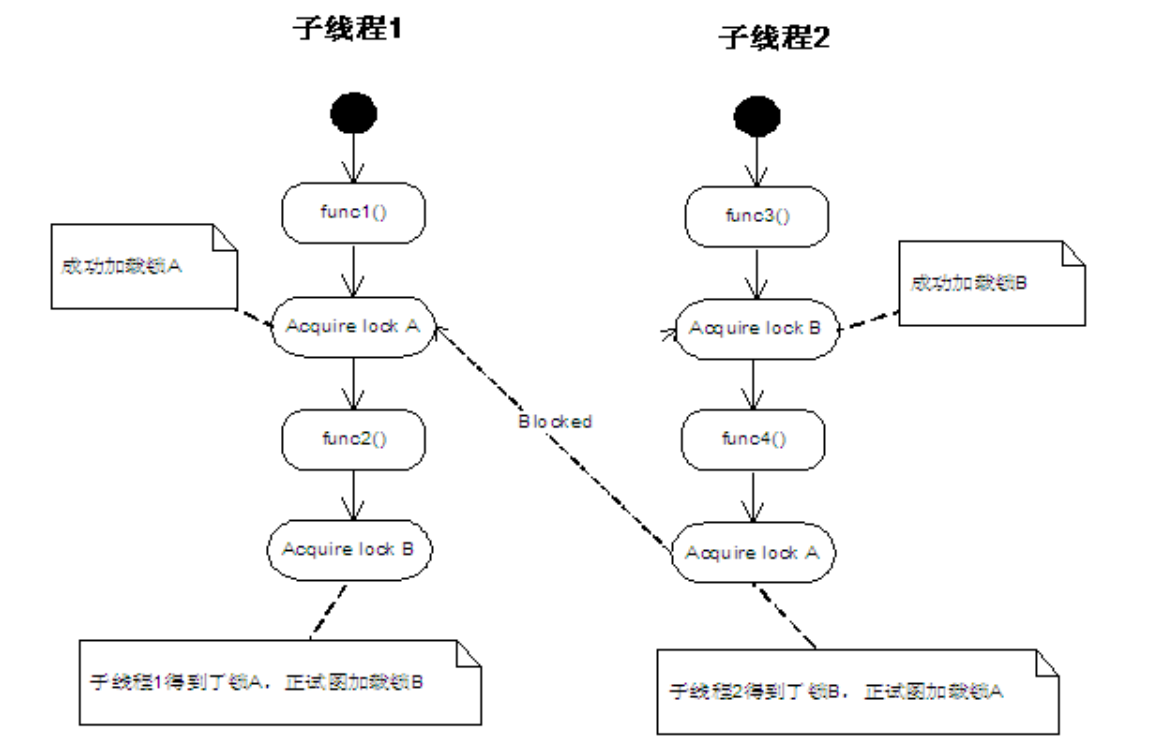
使用pstack和gdb工具对死锁程序进行分析
# 编译测试程序
g++ -g lock.cpp -o lock -lpthread
# 查找测试程序进程号
ps -ef|grep lock
# 多次使用pstack,发现状态没有变化的线程,即使发生了死锁的线程
pstack [pid]
pstack [pid]
# 可以使用gdb来针对对应的线程进行调试,发现问题的原因